Building SRE from Scratch
Introduction to site reliability engineering (SRE) and how you should monitor and keep your systems fast and reliable as they scale.
By Ernese Norelus and Erhan Saygi

In the cloud era, customer experience is the new mantra for any serious business, a mission statement. The customer experience, usability, and accessibility are determined at the edge, where websites are expected to be always available [24/7/365]. Reliability is what matters after all for the users; an unused app has no value to the users and the business.
These days, every company is a technology company that drives transformative changes. Companies build their entire business strategy around cloud capabilities. Making this a significant operational challenge for them. Any degradation of performance and customer experience will result in a loss of money, revenue, and opportunities and cause a big issue with traditional operations [modus operandi] not able to cope with the observability, including monitoring and alerting in real-time.
Why does Site Reliability Engineering (SRE) exist? The agile movement promotes the importance of collaborative efforts between cross-functional teams, and this gave birth to DevOps. DevOps is about drilling down on your own organization’s specific problems and challenges. It is also about achieving speed, efficiency, and quality. In essence, it is a culture, a movement, a philosophy of values, principles, methods, and practices to achieve the desired outcome for the organization. This velocity has created some instability where developers were moving faster than ever and creating a challenge for the operations teams. The IT operations teams were not equipped to deal with such speed creating significant bottlenecks and backlogs for them, not being able to cope with the pace, leading to uncontrolled instability in production where systems became unreliable. Thus, a need for SREs created by Google: “A group of developers who can apply engineering expertise to operations problems.” *
SRE is a prescriptive way to do DevOps. It is a mindset to system administration tasks, which focuses on tenets of operating a service through enabling developers and operations by lowering delivery and incident management lifecycles time and reducing toil. The daily tasks of an SRE team consist of:
- Availability
- Latency
- Performance
- Efficiency
- Change management
- Monitoring and alerting
- Emergency response
- Incident response
- Preparation
- Capacity planning
So, what is Site Reliability Engineering (SRE)?
The role of the SRE team is to operate applications in production “mission-critical systems” and do whatever is necessary to keep the site up and running. It is often defined as a software engineer doing operations work. The SRE teams have the responsibility for maintaining and establishing service level indicators (SLIs), objectives (SLOs), agreements (SLAs), and error budgets for their systems and make sure these are met. They are expected to spend a certain amount of their time doing operational work (making sure systems work as expected) and also improving the systems they manage. SREs focus on writing software to automate processes and reduce toil. Toil is considered manual activities on a system, anything that is not currently automated.
SRE’s strategic goals are to:
- Make deployment easier
- Improve or maintain uptime
- Establish visibility into the application performance
- Set SLI’s and SLO’s and error budgets
- Increase speed by assuming calculated risks
- Eliminate toil
- Reduce the cost of failure to lower new feature cycle time.
SLOs with consequences and SLIs
Service Levels Objectives (SLOs) are simply the agreements between the SRE teams and the product owners or line of business (LOB). The metrics heavily depend on the nature of the system the team is managing. Service Level Indicators (SLIs) are the quantitative measures defined for a system, also knows as “what we are measuring.” The indicators depend on the system under management. For a typical web application, these indicators could be availability, request latency, or error rates. However, for example, a Hyperledger Fabric Blockchain application might use the endorsement and ledger commit rates per second to measure the throughput of the network.
SRE teams will eventually manage multiple systems. Defining a standard set of SLIs across various applications will help the team to standardize monitoring, logging, and automation across the stack.
SLOs are the target value or range the system should operate “how good should it be.” These are expected operational values for the SLIs defined before. For example, a blockchain network has to sustain transaction throughput of 50 to 100 transaction commit rate with less than 5 seconds of end to end latency.
There might be a tendency to overengineer SLI and SLOs. It is essential to keep them simple in the beginning. As your understanding of the system grows over time, you can set more strict targets.
SLA key business values
Service Level Agreements (SLAs) come into play when the customer is unhappy about the service rendered, a failure to deliver according to the agreement in question; it may be the reliability of a system. SLAs are agreements between the product and its end-users, contracts with customers about the reliability of the service, simply stated as “SLA = SLO + consequences.” SRE teams might not be involved in the process of defining SLAs. However, they need to make sure SLO’s are met.
SLA typically contain calculations around minutes of uptime for the service over some time.

A 99.9% is a three 9s uptime allows for 1m 44s of downtime per day. This downtime is 10.1m, 43.8m, and 8.78h of downtime per week, month, and a year, respectively, as shown above in the matrix.
As an example, the SLA may guarantee 99.9% uptime for telecommunication lines; thus, the service can only go down 0.1% downtime beyond it is considered a violation of the SLA, and consequence will follow in the form of penalty.
Reducing toil and controlling SRE team workloads
Toil is tedious, manual, work perform by SRE teams. In your day to day work, whether you are a software developer or an architect you can be doing tasks that you do not enjoy. These are usually manual, boring and repetitive tasks that can lead to mistakes. SRE teams will also have to perform similar tasks. However, this is one instance the SREs can put their development skills in use and eliminate the manual processes as much as possible. It is a good practice to have SREs spend up to 50% of their time on improving the systems that they manage.
Error budget
An error budget is a tool used by SRE teams to balance service reliability and calculated as follow:
Availability = (Number of good events / Total events) * 100Error budget = (100 — Availability) = failed requests / (successful requests + failed requests)
An error budget is 100 minus the SLO of the service. A 99.99% SLO service has a 0.01% error budget.
An error budget is another example of an SLO where each service is subject to its SLA with a penalty clause. It measures how much room you have to meet your other SLO’s. For example, if you have a Service Level Indicator, which says 99.99% transactions have to be committed to ledger within 5 seconds, only 0.01% of the transactions can exceed 5 seconds. A fine day after a major release, you might realize a slowness in the system and suddenly deplete all of your error budgets. Remember, change is the most significant cause of the outage, and launches are big sources of change.
If you are consistently exceeding your error budget, you will need to re-look at some of your SLO’s and processes.
- Are you introducing too many changes in a single release? Please keep it simple and break your releases into smaller chunks.
- Are the SLO’s too strict? You might need to negotiate and loosen the SLOs.
- Are there any manual steps in your release process that is causing problems? Try to automate and test.
- Is the architecture of the system fault tolerant? Hardware fails, network packages get lost, up or downstream applications can misbehave. Your system architecture should be able to tolerate the failures.
- Does the development team tackle technical debt? In a rush to release new features, technical debt often gets overlooked.
- Is your monitoring and alerting catching the leading indicators? Growing queue sizes, network slowdown, having too many lead changes, etc. can lead to downstream incidents.
- Do you monitor your logs regularly and keep them clean? There might be warnings on your logs that do not cause immediate problems. However, coupled with other infrastructure issues, those warnings can lead to major incidents.
The four golden signals for monitoring distributed systems
The SRE four golden signals are some of the basic principles and best practices for building successful monitoring and alerting systems. They are a critical part of your service level objectives (SLOs) for large-scale production applications. Their goals are to help identify and remediate any potential weaknesses in your system. They address your infrastructure concerns proactively. Whenever your operations team needs quick visibility into problems, and need to track the latency, traffic, errors, and saturation for all services in near real-time.
Let’s briefly describe each one of the signals, then see how to leverage the four key metrics to monitor your system:
- Latency: latency is the time delay between the sender and the receiver of the information, and it is measured in milliseconds (ms). And the cause is often due to packet loss, network congestion, and network jitter known as “packet delay variance.” Latency has a direct impact on the customer experience, translated into a latency of successful requests and the latency of failed requests.
- Traffic: traffic is the stress from the amount of work done on the system. It’s measured by query per second (QPS) or transaction per second (TPS). The business measures this by volume: the key performance indicator (KPI) is the number of people coming to the site at a given time. It’s a direct relationship with business value.
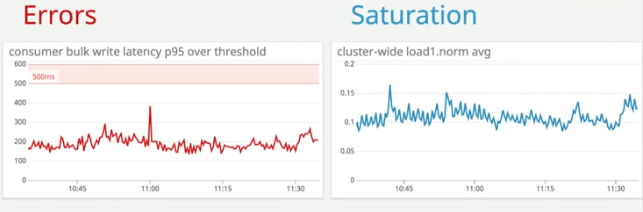
- Errors: errors are measured based on errors happening across the entire system. What is deemed as an essential indicator of the service’s error rate! There are two categories of errors, explicit errors such as a failed HTTP request (500 error codes, for example). And an implicit error would be a successful response but with the wrong content or long response time.
- Saturation: saturation defines how overloaded the service is. It measures the system utilization, emphasizing the resources and the overall capacity of the service. Often this applies to resources like CPU utilization, memory usage, disk capacity, and operations per second. Dashboards and monitoring alerts are ideal tools to help you keep an eye on these resources and help you proactively adjust capacity before they become saturated.
- Utilization: although not recognized part of the “four golden signals,” is it worth mentioning; utilization tells how busy the resource or system is. It’s expressed in % (percent) and varies from 0–100%.
We all agree that these signals are important and must be monitored. How to get started? For the sake of simplicity, let’s create a very rudimentary matrix that takes into consideration the very basic and traditional resources, such as CPU, disk, network, and RAM for a start.

The significant benefits of the golden signals are with its ability to alert, troubleshoot, and tuning & capacity planning:
- Alerting can inform you went something is wrong.
- Troubleshooting can help find & fix the problem with root cause
- Tuning & capacity planning can help make things better over time with the right metrics, logs, and traces collected from monitoring the systems.

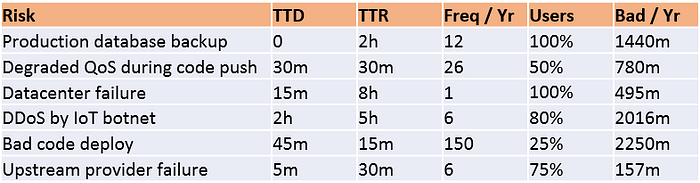
Risk Analysis
Risk analysis is defined as follow: a list of the items that may cause an SLO violation
- TTD (time-to-detect)
- TTR (time-to-resolve)
- Freq / Yr (frequency of error per year)
- Users (percentage of the users affected)
- Bad / Yr (bad minutes per year and also equates to the error budget)
SREs embrace risk in a controlled fashion by using an error budget to control the level of risk that is acceptable and risk and make informed decisions about when changes should be made in conjunction with SLIs and SLOs. If required, the SRE teams can control the release cycle.
Risk = TTD * TTR * (Freq /Yr) * (% of users) If TTD = 0,Risk = TTR * (Freq /Yr) * (% of users)
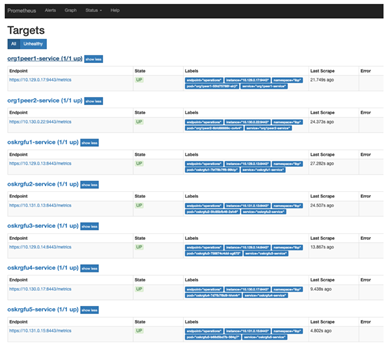
Monitoring and Alerting
Monitoring is a good way to observe how a system operates and alerts are the events that can be triggered when a system is, or about to be, broken. Therefore, the SRE teams have to build reliable and meaningful monitoring systems.
There are tools that we can use to build good monitoring systems. Prometheus is an open source application used for event monitoring and alerting. It records real-time metrics in a time series database built using a HTTP pull model. For example, Prometheus can be configured to pull metrics from a Hyperledger Fabric Blockchain nodes.
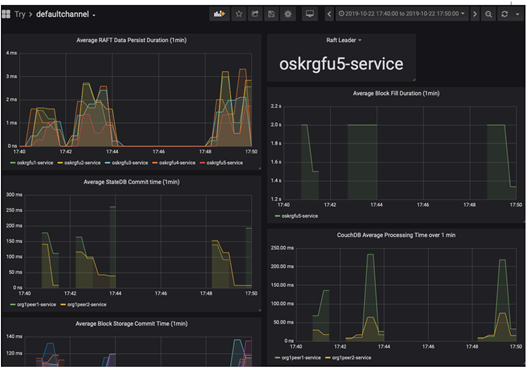
You can configure Grafana to build visualizations and dashboards to query Prometheus.
Facilitate Postmortems
When you are building the SRE function in your organization, one important but often forgotten aspect is postmortem analysis, “postmortem are meant to be blameless.” It can be defined as a chance for an organization to learn from the mistakes it makes. Postmortems should be conducted reasonably soon after the incident is resolved. In a complex enterprise IT environment, the components and applications will eventually fail. The failure could be due to a deployment error, a software bug introduced in a recent release or simply a malfunctioning hardware. Documenting the root cause of the incident together with short and long term fixes applied and circulating across the development and SRE teams is important to retain the knowledge gained in the enterprise. The findings from an incident can be used as a preventive fix to other systems or could be a reference point for a similar incident in the future. Well implemented, postmortems should be easily accessible, and kept is a repository for future access.
How do you get a reliable service?
The role of the SRE team is to operate applications and do whatever is necessary to keep the system up. Below are some of the tactics and possible tools for SREs to perform their daily activities through phases:
Phase 1: Development
- Pipelining
- Load and scale consulting
Phase 2: Pilot
- Monitoring
- On-call + blameless postmortems
- Consolidated + searchable logging
- SLI / SLO review with product managers
- Infrastructure as code
Phase 3: Production
- Canary deployment + automated rollbacks
- Load and scale implementation
- Application performance monitoring
- Chaos engineering
Conclusion
What does it mean to operate reliably? This blog post attempted to cover the fundamental concepts and techniques required to build a successful SRE team. It discussed how to identify and remediate incidents proactively by focusing on observability through improved metrics, logs, traces, and dashboards. Looked at what SLOs, SLIs, and SLAs are. Saw how essential tools like an error budget and a risk analysis could be used to guide the decisions necessary to balance your investment in reliability vs. investing in application features or other business priorities — elaborated on the four golden signals for monitoring distributed systems.
Co-author
Erhan Saygi, Blockchain Labs Architect at IBM
Attribution
Special thank you to Amy Xin from Marketing and Communications IBM Garage for proofreading the early draft before publishing. Also, thank you to the IBM Garage Singapore Engagement Manager team: Yvette Lin, and Jenny Goh, for reviewing. Chun-Yin Wong, Software Client Architect and Kok Wai Ong, Technical Sales.
References
Curious about SRE, please refer to the links below where you can find many reads on how to master the core concepts that can be adopted quickly and without spending months in trying to figure out “the right way to do stuff”:
- Seeking SRE
- So you want to be an SRE?
- Site Reliability Engineering
- The Site Reliability Workbook
- How to Monitor the SRE Golden Signals
- The four Golden signals for collecting metrics
- Building Blocks for Site Reliability Engineering
- SRE: Observability: Metric Namespaces and Structures
- Showing the Value of Site Reliability Engineering (SRE)
- Defining network performance with Google’s 4 golden signals
- When It Comes to Cloud Application Management, Start with the Golden Signals
- The 4 Golden Signals of API Health and Performance in Cloud-Native Applications
- AWS re:Invent 2018: Building SRE from Scratch at Coinbase during Hypergrowth (DEV315-S)
Bring your plan to the IBM Garage.
Are you ready to learn more about working with the IBM Garage? We’re here to help. Contact us today to schedule time to speak with a Garage expert about your next big idea. Learn about our IBM Garage Method, the design, development and startup communities we work in, and the deep expertise and capabilities we bring to the table.
Schedule a no-charge visit with the IBM Garage.
